Copyright © 2004-2005 Leo Rutten
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. See www.gnu.org/copyleft/fdl.html.
| Wijzigingen | ||
|---|---|---|
| Herziening $Revision: 1.4 $ | $Date: 2005/02/04 10:15:11 $ | RL |
| Deel 1 en 2 samengevoegd, smartpointer verwijderd | ||
| Herziening 0.1.0 | 12/ 9/2002 | RL |
| Omzetting van Lotus WordPro | ||
Samenvatting
Deze tekst geeft een inldeiding op de programmeertaal C++.
Inhoudsopgave
- 1. Inleiding
- 2. C constructies met een andere betekenis in C++
- 3. De klasse in C++
- 4. Bewerkingen in een klasse
- 5. Dynamische objecten
- 6. Objecten binnen objecten
- 7. Klassen afleiden
- 8. Virtuele klassefuncties
- 9. Constante objecten
- 10. Statische leden in een klasse
- 11. De [] operator bij reeksen
- 12. Sjablonen: algemene reeksen
- 13. Uitzonderingen
- 14. Een algemene reeks met uitzondering
- 15. Reeks template met automatische uitbreiding
- 16. Pointers opslaan in een container
- 17. Een container als klassevariabele
- 18. De STL containerbibliotheek
- 19. Qt Voorbeelden
- 20. Bibliografie
Lijst van figuren
- 7.1. Erfenisvoorbeeld
- 7.2. Erfenisvoorbeeld met klassevariabelen
- 8.1. Twee klassen met een gemeenschappelijke superklasse
- 15.1. nvreeks.h
- 15.2. cppvb17.cpp
- 16.1. cppvb18.cpp
- 17.1. cppvb19.cpp
- 18.1. stlvb1.cpp
- 18.2. stlvb2.cpp
- 18.3. dbg-geheugen.h
- 18.4. stlvb3.cpp
- 19.1. UML Diagramma van het Figuren voorbeeld
Inhoudsopgave
In de geschiedenis van het programmeren duiken er regelmatig slagwoorden op, die telkens een nieuwe programmeerstijl verdedigen. Een voorbeeld hiervan is het begrip gestructureerd programmeren, dat jaren geleden het tijdperk van de goto-loze programmeerstijl inluidde. Deze programmeerstijl was een stap vooruit in het schrijven van duidelijke en leesbare programma's. Een nieuw slagwoord dat de jongste jaren als adjectief opduikt is het woord object georiënteerd. Dit is een term die velen gebruiken. Zo spreekt men over een object georiënteerde besturingssystemen, object georiënteerde programma's en ook object georiënteerde programmeertalen. Vooral dit laatste is een modewoord. Velen beweren immers in C++ te programmeren, maar eigenlijk bedoelen ze dat hun C programma met een C++ compiler wordt vertaald. Dezelfde verwarring treedt op bij vakatureaankondigingen waarin geëist wordt dat de kandidaat een goede kennis heeft van C++. Aan deze eis is dikwijls niet te herkennen of men in het betreffende bedrijf wel in C++ programmeert. Misschien maakt men alleen maar gebruik van een C++ compiler om C programma's te vertalen. Het is namelijk zo dat er tegenwoordig geen C compilers voor PC meer bestaan. Bijna alle fabrikanten bieden een compiler aan, die C en C++ kan vertalen. Omdat men met object georiënteerde technieken betere programma's kan ontwerpen en omdat de enige manier om te achterhalen of object georiënteerde technieken wel echt beter zijn dan conventionele technieken, zit er niets anders op dan een object georiënteerde taal te leren.
Met deze tekst krijg je een eerste kennismaking met een object georienteerde taal. De kennismaking verloopt aan de hand van C++ voorbeelden. Een andere mogelijkheid zou zijn gebruik maken van de recent ontstane taal Java. Deze taal heeft veel weg van C++ maar is ontdaan van alle onhebbelijkheden die in C++ voorkomen. Java is ontworpen door de firma Sun en is onafhankelijk van de gebruikte computer.
Object georiënteerde talen hebben een aantal specifieke kenmerken die ze onderscheiden van niet object georiënteerde talen. Deze eigenschappen zijn:
Het is een gekende techniek om gegevens die een sterke relatie met elkaar hebben, te groeperen in een structuur of wat met in object georiënteerde termen een klasse noemt. Deze groepering maakt het gemakkelijker om het overzicht op de gegevens binnen een programma te bewaren.
Hiermee wordt bedoeld dat niet alleen gegevens maar ook acties die inwerken op deze gegevens worden gegroepeerd binnen een klasse. Deze techniek laat toe om de gegevens binnen een klasse af te schermen van de buitenwereld. Wie deze gegevens wil raadplegen om veranderen moet dit doen via speciale functies die bij de klasse horen. De toegang tot de gegevens is niet direct maar indirect. De acties of functies binnen een klasse worden in de object georienteerde wereld methoden genoemd. Het voordeel van deze techniek is de mogelijkheid om achteraf nog wijze waarop de gegevens binnen de klasse opgeslagen worden, gemakkelijk te wijzigen.
Als op een zekere dag blijkt dat de gegevensopslag binnen een klasse uitgebreid moet worden, dan zal men in plaats van de klasse te wijzigen een afleiding maken van deze klasse. De nieuwe klassen erft alle gegevens en methoden van de klasse waarvan geërfd wordt. Aan de nieuwe klassen kunnen andere gegevens en methoden toegevoegd worden of kan een overgeërfde methode vervangen worden door een nieuwe versie. Dit is het principe van de erfenis.
In de klassieke programmeertalen zorgt de linker ervoor dat de werkelijke adressen van de functies ingevuld wordt bij elke CALL instructie. Dit is het principe van de vroege of statische verbinding. In object georienteerde talen kan deze verbinding uitgesteld worden tot het uitvoeren van het programma. Vlak voor de uitvoering van de CALL wordt het adres van de functies opgezocht. Dit mechanisme geeft een verhoogde flexibiliteit en is de kern bij het object georienteerd programmeren.
Deze term wordt gebruikt om aan te geven dat de oproep van een functie of methode soms een ander gedrag geeft. Het gedrag van de opgeroepen methode is afhankelijk van de gegevens. Deze speciale afhankelijkheid tussen gegevens en methode maakt het mogelijk om delen van programma's te ontwerpen die een zekere vorm van algemeenheid bewaren. Hiermee verhoogt de kans dat deze programmadelen later herbruikt worden. Het mechanisme om polymorfie toe te laten is de late verbinding. Een voorbeeld uit het dagelijkse leven maakt polymorfie duidelijk: als we iemand de opdracht geven om een voertuig dan zal de man (of vrouw) in kwestie zijn gedrag aanpassen naargelang hij (of zij) een gewone auto moet wassen of een autobus.
Een van de object georienteerde talen is C++. Andere talen zijn Eiffel, Smalltalk, ObjectC, Simula en Turbo Pascal vanaf versie 5.5. Verder zijn er object georiënteerde uitbreidingen op reeds bestaande talen; dit geldt onder andere voor Lisp en Prolog. Aan dit lijstje wordt uiteraard de jongste taal Java toegevoegd.
De taal C++ is ontworpen door Bjarne Stroustrup en is volledig gebaseerd op C. C op zijn beurt is afgeleid van zijn voorganger BCPL. De commentaarstarter // die in C++ ingevoerd is, bestond al in BCPL. Heel wat concepten van C++ (de naam C++ werd in de zomer van 1983 uitgevonden) zijn afgeleid van andere programmeertalen. Het klasseconcept met afleidingen en virtuele functies werd van Simula67 overgenomen. De mogelijkheid om bewerkingstekens een andere betekenis te geven en om overal in het programma declaraties van variabelen te schrijven is van Algol68 overgenomen. Zo ook komen de ideeën voor templates en exceptions uit Ada, Clu en ML. C++ werd door de auteur ontworpen voor eigen gebruik. De eerste versie was geen eigen compiler maar wel een C naar C++ omzetter. Dit programma heette cfront. Door de stijgende populariteit van C++ bleek toch een standaardisatie noodzakelijk. Deze stap in gang gezet binnen ANSI als de X3J16 commissie in 1989. De ANSI C++ standaardisatie zal vermoedelijk ook deel uitmaken van een internationale ISO standaard. Tijdens de periode van het ontstaan tot de standaardisatie is C++ geëvolueerd. Een aantal wijzigingen zijn er gekomen na het opdoen van praktische ervaring.
Oorspronkelijk werd C ontworpen om assembler te vervangen. Ook C++ kan in deze optiek gebruikt verder gebruikt worden. Met andere woorden C++ staat dicht bij de machine. Van de andere kant is C++ bedoeld om de complexiteit van een probleem in kaart te brengen. Door een klassehierarchie op te bouwen is het mogelijk om een klare kijk te behouden op de gegevens en bijbehorende acties in een probleem. Hierdoor is het mogelijk dat één persoon met C++ programma's van meer dan 25.000 regels kan ontwerpen en onderhouden. In C zou dit veel moeilijker zijn.
Veel C programmeurs blijven liever bij C en zijn niet geneigd om C++ te leren. Hun argumenten zijn dikwijls als volgt:
C++ is een moeilijke taal. De concepten zijn veel abstracter en de mechanismen in de taal zijn op het eerste zicht niet erg duidelijk. Waarom een moeilijke taal zoals C++ gebruiken als het met eens simpele taal zoals C ook gaat.
Bij C++ is het veel moeilijker om de programmauitvoering te volgen. Om de haverklap worden constructors uitgevoerd. Door het mechanisme van de late binding weet je niet direct waar je terecht komt bij de stap voor stap uitvoering.
Sommigen willen toch de principes van het object georienteerd programmeren volgen, maar doen dit liever in C. Deze werkwijze is nogal omslachtig.
Bij C++ is de programmeur verplicht om tijdens de analyse zijn denkproces aan te passen aan het object georienteerd ontwerpen. Dit pijnlijke denkwerk gebeurt reeds voor het programmeren en kan niet omzeild worden. In deze analysefaze ben je verplicht om diep te denken over gegevens en acties en hun onderling relaties. Het resultaat van dit denkwerk is het objectenmodel van het probleem. Dit model dient als leidraad tijdens het programmeerwerk. Tijdens de testfaze zal dan blijken dat er minder denk- en programmeerfouten zijn en bijgevolg het programma sneller afwerkt zal zijn.
Tijdens de geschiedenis van de programmeertalen zijn er heel wat programmeerprincipes opgedoken. Een van de eerste principes is het programmeren met procedures. Hierbij is het de bedoeling om alle acties die nodig zijn om een bepaalde taak uit te voeren worden in een routine, procedure of functie ondergebracht. De analyse die deze groepering vooraf gaat is vooral gericht naar uitvoerbare acties. Er ontstaat en hiërarchie van procedures.
Voor het controleren van de volgorde waarin acties worden uitgevoerd werd eerst de goto gebruikt. Tegenwoordig wordt deze constructie niet meer gebruikt (tenzij in assembler). De if-then-else is er in de plaats gekomen. Dit principe heet gestructureerd programmeren. Deze stijl wordt alle moderne programmeertaal mogelijk gemaakt.
Na een aantal jaren is gebleken dat een goede data-analyse belangrijk is. Een aantal procedures die betrekking hebben op dezelfde gegevens worden in een module gegroepeerd. De data binnen de module mag niet rechtstreeks toegankelijk zijn, maar gebeurt door middel van procedures. Dit is het modulair programmeren. Hierbij wordt het principe van de data-hiding toegepast. De wijze waarop de data is opgeslagen is niet gekend door de gebruiker van de module. Het modulair programmeren laat ook toe grotere programma's te ontwerpen. In C is een module een apart .C bestand waarin de gegevens in globale variabelen worden bijgehouden. Om de data-hiding mogelijk te maken moet het woord static aan elke declaratie voorafgaan. Deze methode heeft een nadeel: elke module stelt slechts één gegevensgroep voor, bijvoorbeeld een tabel met strings. Als we meerdere gegevensgroepen willen maken moeten we struct gebruiken. Hiermee verliezen we de data-hiding. De taal C is daarom niet geschikt om op een succesvolle manier gegevens voor de gebruiker te verbergen. Door dit nadeel is het beter om C te verlaten en C++ te gebruiken. C++ kent het principe van de klasse. Hiermee is een perfecte data-hiding mogelijk
Bij het modulair programmeren ontstaan modules. Bij nieuwe projecten is het dikwijls lastig om bestaande modules opnieuw te gebruiken. Dikwijls zijn er kleine aanpassingen nodig of wordt toch maar de hele module herschreven. Het herbruiken van reeds bestaande programmatuur is niet gemakkelijk bij het modulair programmeren. Bij het object georienteerd programmeren is het mogelijk om afleidingen te maken van bestaande klassen. In de nieuwe klassen kunnen dan de kleine wijzigingen gebeuren. Een andere ontwerptechniek is het ontwerpen van een klasse waarin een aantal functies alleen maar als prototype voorkomen. In de afleiding van deze klassen wordt de implementatie van deze functies ingevuld. Door deze techniek is het mogelijk om een klasse te maken die nog algemeenheid als eigenschap hebben. Een algemene (of in OO termen: abstracte) klasse is niet bedoeld om hiermee variabelen te declareren. Van een abstracte klasse worden afleidingen gemaakt en deze afleidingen worden gebruikt om variabelen te declareren. Door de techniek van de afleiding ontstaan er hiërarchieën van klassen. Die maken het mogelijk om de functionaliteit en gegevens in een groot programma goed in kaart te brengen. C programmeurs die klagen over de moeilijkheidsgraad van C++ klagen over het feit dat ze een OO analyse van gegevens/acties moeten uitvoeren; iets dat zij tot nu toe nooit deden. Daarom is C++ leren niet zomaar weer een nieuwe taal leren, het is een andere manier van denken.
Als besluit op deze inleiding geven we de tegenargumenten die voor C++ pleiten:
De concepten van een OO taal zijn abstracter omdat het denken tijdens een OO analyse abstracter is. Deze hogere graad van denken loont wel de moeite. Hiermee worden vroegtijdig de elementen (gegevens en bijbehorende acties) van het probleem gestructureerd en worden tegenstrijdigheden die later zouden kunnen opduiken bij onderhoud of wijziging vermeden.
Het is inderdaad veel moeilijker om een C++ programma stap voor stap te volgen, want we worden geconfronteerd met alle details van alle klassen die doorlopen worden. Het is beter om niet stap voor stap te debuggen, maar wel op klasseniveau. Test elke klasse een voor een. Door de data-hiding is de relatie tussen de verschillende klassen minimaal. Elke klasse kan daarom als een op zich bestaand domein beschouwd worden.
Het is beter om OO te programmeren met een taal die dit principe ondersteund. Een goede programmeur kan wel in zekere mate OO principes in C toepassen, maar dit gaat gepaard met veel pointers naar functies, void * pointers en cast bewerkingen. Dit zijn allemaal constructies die gemakkelijk fouten introduceren.
Niet object georienteerde verschillen tussen C en C++
Normaal gezien is het mogelijk om een C programma te compileren met behulp van een C++ compiler. Er zijn wel enkele kleine verschillen tussen beide compilers voor wat betreft de C syntax.
Inhoudsopgave
We geven hier een overzicht van de belangrijkste taal elementen die anders zijn in C++ dan in C.
In C++ is er geen beperking op de lengte van namen
De C++ compiler moet eerst een prototype van een functie gezien hebben voor dat deze functie opgeroepen kan worden.
In C++ betekent de declaratie f() een functie zonder parameter. In C zouden we in dit geval void moeten schrijven
De oude stijl van parameteroverdracht in C is verboden in C++.
Een karakterconstante is in C++ van het type char, in C is dit int.
Dit is een nieuw type in C++. Het referentietype maakt het mogelijk om een variabele te declareren die als synomiem van een andere variabele dienst doet.
int a; int &x = a; int &y; // Fout: initialisatie ontbreekt x = 5; // a is nu 5
De variabele is een gewoon geheel getal. De variabele x is een referentievariabele die verwijst naar de variabele a. Voor x is er geen opslagruimte voor een int. Als x gewijzigd wordt, wordt de inhoud van a gewijzigd. Een referentievariabele moet geinitialiseerd worden bij de declaratie. Daarom is de declaratie van y fout. Het is niet mogelijk om na de declaratie de referentievariabele naar een andere variabele te laten verwijzen.
De referentievariabele wordt dikwijls als formele parameter gebruikt. Hier is een klassiek voorbeeld:
void swap(int &x, int &y)
{
int h;
h = x;
x = y;
y = h;
}
void main()
{
int a = 5;
int b = 6;
swap (a, b); // verwissel a en b
}
Bij het gebruik als parameter gedraagt een referentietype zich als een VAR parameter in Pascal. Het voordeel is het feit dat in de functie swap de variabelen x en y er als een gewone variabele uitzien en niet als een pointervariabele.
Inhoudsopgave
C++ kent niet alleen het type struct maar ook het type class. Beiden kunnen gebruikt worden om gegevens in te kapselen. Dit doen we om gegevens, die sterk verbonden zijn, samen te brengen onder een noemer. Het sleutelwoord class is nieuw in C++ en laat de bescherming van de gegevens binnen een klasse toe.
Het eerste voorbeeld heeft wat te maken met grafische weergave van gegevens. In een grafische omgeving moeten we de coördinaten van een punt op het scherm bijhouden. Dit doen we door de coördinaten van een plaats op te slaan in een klasse:
class Punt
{
int x;
int y;
};
De klasse Punt bevat dus de velden x en y. Deze vorm van groeperen kennen we al van C. Met de klasse Punt kan een variabele gedeclareerd worden en we kunnen trachten om de velden x en y te bereiken.
Punt p1;
De variabele p1 is van het type Punt en is in staat om 2 coördinaten te onthouden. Dit is niet meteen zichtbaar aan de variabele. Dit is het principe van de inkapseling. We gebruiken de term object om een variabele van een zekere klasse aan te duiden. Als we het in de toekomst over objecten hebben, dan bedoelen we hiermee variabelen of stukken dynamisch geheugen waarin zich informatie van een zekere klasse bevindt.
Als we de leden van het object p1 willen bereiken, dan zouden we het volgende kunnen uitproberen:
void main()
{
Punt p1;
p1.x = 50;
p1.y = 70;
}
Helaas geeft dit programma twee compilatiefouten. De twee velden x en y zijn niet toegankelijk van buiten het object. Als we binnen de definitie van de klassen niet een van de woorden private, protected of public zijn alle leden privaat, private dus. We hadden evengoed dit kunnen schrijven:
class Punt
{
private:
int x;
int y;
};
Op deze wijze wordt duidelijk weergegeven dat de leden x en y niet publiek toegankelijk zijn.
Omdat de leden van de klasse Punt niet publiek toegankelijk zijn is er een probleem om bijvoorbeeld de variabele p1 te initialiseren of om de waarden x en y van een Punt object te weten te komen. Daarom zijn we verplicht tot de leden van een klasse via lidfuncties te organiseren. Een lidfunctie is een functie die deel uitmaakt van een klasse. Dikwijls wordt ook de term methode voor dit soort functies gebruikt. Er is een speciale vorm van een lidfunctie die enkel voor de initialisatie van een object wordt gebruikt. Deze vorm wordt constructor genoemd. Een constructor krijgt als naam de naam van de klasse.
class Punt
{
private:
int x;
int y;
public:
Punt(int ix, int iy);
};
Binnen de klassebeschrijving noteren we een prototype van een functie. Omdat we voor de functienaam de naam van de klasse kiezen, is deze functie een constructor. We voorzien de constructor van twee formele parameters ix en iy. Dit betekent dat we aan de constructor twee getallen kunnen meegeven die dienen voor de initialisatie van het object. Bij een constructor mogen nooit een return type noteren; parameters mogen wel. In dit voorbeeld zijn er twee parameters.
Wat deze constructor moet doen, is nog niet vastgelegd. Binnen de klasse staat alleen maar een prototype. Nu zijn er twee manieren om de implementatie vast te leggen.
We noteren de implementatie van de constructor buiten de accolades van de klassebeschrijving. Om aan te geven dat het hier gaat over een lidfunctie van de klasse Punt moeten we nog eens de klassenaam aan de functienaam laten voorafgaan. Tussen de klassenaam en de functienaam schrijven we twee dubbele punten.
Punt::Punt(int ix, int iy)
{
x = ix;
y = iy;
}
Omdat het hier om een constructor gaat, schrijven we tweemaal Punt . Eenmaal als klassenaam en als functienaam. Binnen de acties van een lidfunctie zijn de dataleden van een klasse vrij toegankelijk. De namen x en y binnen de constructor zijn de twee dataleden van een Punt object. Aan elk van de dataleden wordt een startwaarde toegekend.
Voor het toekennen van een startwaarde is er bij constructors aan andere schrijfwijze mogelijk. Hierbij wordt na een dubbele punt de lijst van te initialiseren datavelden geschreven met telkens de startwaarde erbij:
Punt::Punt(int ix, int iy) : x(ix), y(iy)
{
}
Deze schrijfwijze mag alleen maar bij constructors toegepast worden.
We kunnen de implementatie van de constructor ook binnen de klasse noteren. Het voordeel is dat we minder schrijfwerk hebben. Het nadeel is dat als we de implementatie van de constructor wijzigen, dan moet er binnen de klassedefinitie gewijzigd worden. Vermits we alle klassedefinities in headerbestanden onderbrengen, veroorzaakt dit de hercompilatie van alle .cpp bestanden die van deze klasse gebruik maken.
class Punt
{
private:
int x;
int y;
public:
Punt(int ix, int iy) : x(ix), y(iy)
{
}
};
Voor een constructor maakt het geen verschil uit welke twee opties gekozen wordt. Voor lidfuncties, die dus geen constructor zijn, is er wel een verschil tussen implementatie binnen of buiten de klasse. Dit onderscheid bespreken we later.
Zoals we met een eenvoudig type een variabele kunnen declareren, kunnen we met een klasse een object declareren.
#include <iostream.h>
Punt pg(23, 34);
void main()
{
Punt p1(30, 40);
Punt p2 = Punt(44, 55);
cout << "main\n";
}
Omdat er een constructor is die twee gehele getallen verwacht als parameter, moeten we bij de initialisatie tussen ronde haken twee getallen voorzien. Het is hier dat de constructor in actie treedt. Een constructor kunnen we nooit zelf starten. Een constructor wordt uitgevoerd voor een object, zodra dit object tot leven komt. Voor pg is dit zelfs voor de start van main(). Dit betekent dat voor het starten van main() de dataleden x en y van het object pg met 23en 34 worden gevuld. Daarna start main() en daarna wordt achtereenvolgens de constructor voor p1 en p2 opgeroepen. Dan pas start de uitvoering van printf(). Voor p1 en p2 is telkens een andere schrijfwijze van de initialisering toegepast.
Het is mogelijk om meerdere constructors te voorzien binnen een klasse. Het aantal en het type parameters van alle constructors moeten verschillend zijn. Met andere woorden: elke constructor heeft aan ander prototype. In de klasse Punt hadden we al een constructor met als parameters de coördinaten van een punt. We voegen nu een constructor bij die geen parameters heeft.
class Punt
{
private:
int x;
int y;
public:
Punt(int ix, int iy) : x(ix), y(iy)
{
}
Punt() : x(0), y(0)
{
}
};
De implementatie van deze nieuwe constructor plaatsen we voor het gemak in de klasse zelf. Deze constructor zorgt ervoor de dataleden x en y automatisch 0 worden als we de expliciete initialisatie weglaten bij de declaratie van een object. In de volgende versie van main zien we twee objecten van de klasse Punt; één met en één zonder initialisatie.
void main()
{
Punt p1(30, 40);
Punt p2;
}
Het object p1 wordt met de eerste constructor geinitialiseerd en p2 wordt geinitialiseerd met de tweede constructor. Dit betekent dat de p2.x en p2.y allebei nul worden. De compiler beslist aan de hand van het aantal en het type actuele parameters welke constructor bij de declaratie opgeroepen wordt. Dit is meteen ook de reden waarom er geen twee constructors met hetzelfde prototype mogen zijn.
Het is mogelijk om bij de declaratie een object te initialiseren met een ander object.
void main()
{
Punt p1(30, 40);
Punt p2 = p1;
}
We zouden kunnen verwachten dat de compiler zou eisen dat er een constructor met prototype
Punt(const Punt &x);
voorkomt in de klasse. We hoeven deze constructor echter niet te definiëren omdat dit automatisch gebeurt. Elke klasse krijgt automatisch een constructor die dient voor de initialisatie met een object van dezelfde klasse. Deze constructor wordt copy constructor genoemd; hij kopieert één voor één alle dataleden van het ene naar het andere object. Dit gedrag is hetzelfde als bij het kopiëren van structuren in C. Bij de klassen Punt is het lidsgewijs kopiëren het juiste gedrag. In het bovenstaande voorbeeld worden de datavelden x en y van p1 naar p2 gekopieerd.
Zo kunnen we ook objecten kopiëren met een toekenning. Deze operator kopieert zoals bij de copy constructor alle dataleden.
void main()
{
Punt p1(30, 40);
Punt p2;
p2 = p1;
}
Voor deze bewerking heeft de compiler automatisch een operator voor de = bewerking binnen de klasse bijgevoegd. Het bijvoegen van bewerkingen bekijken we later nog wel.
De twee dataleden van de klasse Punt zijn privaat. Dit betekent dat we niet rechtstreeks toegang krijgen tot de dataleden. Daarom voegen we een klassefunctie bij die de coördinaten van een Punt op het scherm drukt.
class Punt
{
private:
int x;
int y;
public:
Punt(int ix, int iy) : x(ix), y(iy)
{
}
Punt() x(0), y(0)
{
}
void druk();
};
void Punt::druk()
{
cout << "<" << x <<
"," << y << ">";
}
De klassefunctie druk kan zonder meer toegang krijgen tot de dataleden van het object in kwestie. De functie druk kan alleen maar gestart worden met een concreet object:
void main()
{
Punt p1(67,78);
Punt p2(34,98);
p1.druk();
p2.druk();
}
De notatie van de oproep van een klassefunctie is dezelfde als in C voor de toegang tot een veld van een structuur. De naam van het object wordt gevolgd door een punt en de naam van de klassefunctie.
Het is mogelijk om de tijd die nodig is voor de oproep en de terugkeer van een functie te elimineren. Dit is nodig als een klassefunctie zeer kort is.
We gaan twee lidfuncties aan de klasse Punt bijvoegen om de waarden van dataleden x en y terug te geven. We tonen twee versies van de implementatie van de lidfuncties.
Binnen de klasse Punt worden twee prototypes voor haalx en haaly bijgevoegd.
class Punt
{
private:
int x;
int y;
public:
Punt(int ix, int iy) : x(ix), y(iy)
{
}
Punt() : x(0), y(0)
{
}
void druk();
int haalx();
int haaly();
};
De implementaties van de twee functies ziet er zo uit:
int Punt::haalx()
{
return ( y );
}
int Punt::haaly()
{
return ( y );
}
We kunnen deze twee functies expliciet gebruiken om de waarden van de coördinaten op te halen zonder grens van de inkapseling te overtreden. Dit wordt als volgt gedaan:
void main()
{
Punt pp(67, 89);
cout << "<" << pp.haalx()
<< "," << pp.haaly() <<">\n";
}
Bij deze implementatie is er sprake van een echte subroutine. Er is bijgevolg een oproep en een terugkeer. Het nadeel van deze twee functies is dat ze zeer kort zijn; dit betekent dat er meer tijd besteed wordt aan de oproep en de terugkeer (jsr en ret instructies) dan aan de uitvoering van de acties van de functies. Daarom kan gekozen worden voor de inline uitvoering van dit soort van korte functies.
We plaatsen de opdrachtregel van de klassefuncties binnen de definitie van de klasse.
class Punt
{
private:
int x;
int y;
public:
Punt(int ix, int iy) { x = ix; y = iy; }
Punt() { x = 0; y = 0; }
void druk();
int haalx()
{
return( x );
}
int haaly()
{
return( y );
}
};
Door deze notatievorm wordt de functie inline uitgevoerd. Elke oproep in C++ notatie wordt vervangen door de instructies van de opdrachtregel. Het is evident dat deze oplossing alleen efficiënt is bij zeer korte klassefuncties. Het gevolg is wel dat het programma in zijn totale lengte (in machineinstructies uitgedrukt) langer wordt omdat het principe van de subroutine niet wordt toegepast.
Er is een alternatieve implementatie van een inline klassefunctie mogelijk. De implementatie wordt dan toch buiten de klassedefinitie geschreven, maar het prototype bij de implementatie van de klassefunctie wordt voorafgegaan door het woord inline
class Punt
{
private:
int x;
int y;
public:
Punt(int ix, int iy) : x(ix), y(iy)
{
}
Punt() : x(0), y(0)
{
}
void druk();
int haalx();
int haaly();
};
inline int Punt::haalx()
{
return ( y );
}
inline int Punt::haaly()
{
return ( y );
}
C++ kent de mogelijkheid om een nieuwe betekenis te geven aan een bewerkingsteken afhankelijk van de klasse waarop de bewerking betrekking heeft. Zo kan men een andere betekenis geven aan de optelling bij breuken en bij complexe getallen. We geven een voorbeeld dat handelt over breuken.
We ontwerpen de klasse om een breuk op te slaan. De klasse krijgt twee dataleden: een voor de teller en een voor de noemer. Beide worden opgeslagen als een geheel getal. De constructor is voorzien van verstekwaarden; zo krijgt een breuk de waarde 0/1 wanneer de initialisatie ontbreekt.
// breuk.h
class Breuk
{
public:
Breuk(int t=0, int n=1) : teller(t), noemer(n)
{
}
Breuk &operator++();
Breuk operator+(Breuk b);
private:
int teller;
int noemer;
};
Wanneer we een bewerkingsteken willen definiëren dan geven we de bijbehorende functie een speciale naam. We combineren het sleutelwoord operator met het bewerkingsteken in kwestie. Voor de ++ bewerking wordt dit:
Breuk &operator++();
Deze functie geeft een Breuk als referentietype terug. Dit is nodig omdat de ++ bewerking in uitdrukkingen kan voorkomen. Het terugkeer type is het referentietype omdat de ++ bewerking zowel links of rechts van een toekennig kan voorkomen.
Breuk b1; Breuk b2; b1++ = b2++;
Op dezelfde wijze wordt de functienaam voor deoptelling samengesteld:
Breuk operator+(Breuk b);
In dit geval is er een parameter: dit is de breuk die bij andere breuk wordt opgeteld. Het resultaat van de bewerking is het Breuk type. De bewerking kan zo gebruikt worden:
b3 = b1+b2;
We zouden de bewerlking ook als een functie kunnen starten
b3 = b1.operator+(b2);
Deze schrijfwijze is alleen maar nuttig om te zien hoe de bewerking gestart wordt.
De implementatie van beide bewerkingen worden als gewone klassefuncties geschreven. Voor de ++ bewerking wordt de noemer éénmaal bij de teller opgeteld. Met
return *this;
wordt een referentie naar het huidige object als resultaat teruggegeven.
// breuk.cpp
#include <iostream.h>
#include "breuk.h"
Breuk &Breuk::operator++()
{
teller += noemer;
return *this;
}
Breuk Breuk::operator+(Breuk b)
{
Breuk nb;
nb.teller = teller * b.noemer + noemer * b.teller;
nb.noemer = noemer * b.noemer;
return nb;
}
In de + bewerking wordt een nieuwe Breuk gemaakt. De som van de twee op te tellen breuken wordt in deze nieuwe variabele geplaatst. Met return, in dit geval de som, gaat het resultaat terug naar de oproeper.
In sommige gevallen is het nodig om een bewerking als een functie buiten de klasse te definiëren. Dit is het geval bij de functie die de uitvoer van een Breuk verzorgt. Omdat deze functie toegang moet krijgen tot de private leden van de klasse Breuk maken we de functie een vriend van de klasse Breuk.
friend ostream &operator<<(ostream &os, Breuk b);
Het bovenstaande prototype wordt in de klasse bijgevoegd. Met het woord friend gevolgd door een prototype wordt aangegeven dat een niet-klasse functie toegang krijgt tot alle private leden.
Voor de uitvoer wordt het naar links schuif teken << gebruikt. We schrijven dit teken na het woord operator. De parameters van de uitvoerbewerking zijn het uitvoerkanaal en de Breuk die getoond moet worden. ostream is het type van het uitvoerkanaal. cout behoort tot dit type. Als terugkeertype zien we een referentie naar ostream. We geven het uitvoerkanaal terug als referentie. Dit is nodig omdat de uitvoerbewerking samen met het uitvoerkanaal en de breuk opnieuw als een ostream aanzien wordt. Hierdoor kan men meerdere uitvoerbewerkingen na elkaar schrijven.
(cout << b1) << b2;
In de bovenstaande uitvoer wordt cout << b1 opnieuw als een uitvoerkanaal aanzien. Naar dit kanaal wordt de uitvoer van b2 gestuurd.
De implementatie van de uitvoerbewerking gaat na of de noemer 1 is. Indien ja, wordt alleen de teller getoond. Anders worden teller en noemer gescheiden met een deelstreep getoond.
ostream & operator<<(ostream &os, Breuk b)
{
if (b.noemer == 1)
{
cout << b.teller;
}
else
{
cout << b.teller << "/" << b.noemer;
}
return os;
}
De uitvoerbewerking geeft als resultaat het doorgegeven uitvoerkanaal terug.
We tonen nog een voorbeeld van een hoofdprogramma waarin de klasse Breuk gebruikt wordt.
#include <iostream.h>
#include "breuk.h"
void main()
{
Breuk b;
cout << b << endl;
b++;
cout << b << endl;
Breuk c(1,4);
Breuk d(1,2);
Breuk e;
e = c + d;
cout << e << endl;
}
Inhoudsopgave
Zoals C kent C++ ook het principe van het dynamisch reserveren van geheugen voor gegevensopslag. In C++ zijn voor dit doel de operatoren new en delete ingevoerd.
Met de new bewerking kan geheugen op dynamische wijze gereserveerd worden. In tegenstelling tot C waar malloc() een ingebouwde functie is, is in C++ new een ingebouwde bewerking. Deze bewerking wordt toegepast op de typeinformatie.
De eerste vorm waarin new gebruikt kan worden is de toepassing op een enkelvoudig type. Als we bijvoorbeeld geheugen voor één int willen reserveren dan kan dit zo:
int *pi = new int; *pi = 5;
De toepassing van de bewerking new op het type levert het adres op van een blokje geheugen. In dit geheugen is plaats voor één getal van het type int. In tegenstelling tot C is er geen cast-bewerking nodig.
Dikwijls wordt de new bewerking gebruikt om geheugen te reserveren voor objecten. We gebruiken dan als type-informatie de klassenaam. In het volgende voorbeeld wordt een object van de klasse Punt gereserveerd.
Punt *pu = new Punt;
ofwel, in een andere schrijfwijze:
Punt *pu; pu = new Punt;
Bij het uitvoeren van de new bewerking gebeuren er eigenlijk twee stappen
new reserveert geheugen als nodig is voor de klasse
indien de reservatie gelukt is, wordt nog de constructor uitgevoerd
In het voorgaande voorbeeld wordt de constructor zonder parameter uitgevoerd. Hierdoor worden de dataleden allebei nul.
Bij de klasse Punt is het mogelijk om bij het dynamisch reserveren van een object meteen ook gegevens voor de initialisatie mee te geven. We maken dan gebruik van de constructor met twee parameters.
void fu()
{
Punt *pa;
Punt *pb;
pa = new Punt(23,34);
pb = new Punt(45,56);
pa->druk();
pb->druk();
}
Als in het bovenstaande voorbeeld de functie fu() gestart wordt, worden er twee objecten in dynamisch geheugen gereserveerd. Omdat bij new na de klassenaam twee getallen voorkomen, wordt de constructor met twee parameters gestart. Na het reserveren van twee objecten wordt met de methode druk() de coördinaten in pa en pb op het scherm geschreven. Omdat pa en pb pointers zijn, moet een pijl gebruikt worden om methoden te bereiken.
Als in het voorgaande voorbeeld het einde van de functie bereikt wordt, houden de pointers pa en pb op te bestaan. Vermits ze allebei wijzen naar dynamisch gereserveerd geheugen, zou hierdoor een geheugenlek ontstaan. Daarom moet vóór het einde van de functie het geheugen vrijgegeven worden. Dit doen we met de delete bewerking.
void fu()
{
Punt *pa;
Punt *pb;
pa = new Punt(23,34);
pb = new Punt(45,56);
pa->druk();
pb->druk();
delete pa;
delete pb;
}
Na het woord delete schrijven we de naam van de pointervariabele die wijst naar het dynamisch geheugen. Voor elke new bewerking die in een programma voorkomt moet er een overeenkomstige delete bewerking zijn.
Bij het gebruik van de bewerking new bestaat de mogelijkheid om geheugen voor arrays te reserveren. We schrijven dan na new een arraytype. De waarde tussen de rechte haken mag wel een variabele zijn. Hierdoor kan de lengte van de array dynamisch bepaald zijn. In het volgende voorbeeld krijgt p het adres van een blok van 100 char's.
char *p = new char[100] delete [] p;
Bij het vrijgeven van het geheugen met delete moet aangegeven worden dat het gaat over een array. Daarom moeten voor de variabelenaam rechte haken geschreven worden. De vrijgave van het geheugen moet expliciet geschreven worden voordat een pointervariabele ophoudt te bestaan.
Het is mogelijk om de hoeveelheid geheugen die nodig is binnen de klasse ook dynamisch te reserveren. Op deze manier zijn er geen beperkingen op de lengte van de binnen een klasse opgeslagen gegevens.
In het volgende voorbeeld wordt een klasse Tekst gedemonstreerd. Deze klassen kan gebruikt worden om tekstobjecten te creëren. Om te vermijden dat er conflicten ontstaan als er lange teksten opgeslagen moeten worden, is de opslag van de string binnen een object dynamisch. De klasse Tekst ziet er als volgt uit:
class Tekst
{
private:
char *ptekst;
public:
Tekst(const char *pv = "");
~Tekst();
char *str() const
{
return( ptekst );
}
Tekst &operator=(const Tekst &t);
Tekst &operator+=(const Tekst &t);
Tekst operator+(const Tekst &t);
};
Voor de opslag van de string binnen het object is er het private datalid ptekst. De constructor
Tekst(const char *pv = "");
wordt opgeroepen als een Tekst object met een char string initialiseren. Indien de parameter bij de oproep van de constructor ontbreekt, dan wordt een lege string als verstekwaarde gebruikt.
De implementatie van de constructor is als volgt:
Tekst::Tekst(const char *pv)
{
ptekst = new char [strlen(pv) + 1];
strcpy(ptekst, pv);
}
Met new worden zoveel bytes gereserveerd als de string lang is. Er is ook een extra byte voor de nulwaarde op het einde. Het resultaat van strlen() is immers de lengte van de string zonder de eindnul meegerekend. De originele string wordt in het gereserveerde geheugen gekopieerd. De kopieerbewerking is nodig om ervoor te zorgen dat object een eigen string in eigendom heeft. Indien we alleen het adres van de string zouden kopiëren, dan ontstaat er een situatie waarin een object verwijst naar geheugen die niet door het object wordt beheerd. Dit zou gevaarlijke situatie zijn.
Omdat er in de constructor dynamisch geheugen wordt gereserveerd, is het nodig dat in de klasse ook een destructor bestaat. Het prototype wordt met een tilde geschreven:
~Tekst();
Een destructor heeft geen parameters en geen terugkeertype. Een destructor kan wel virtueel zijn (een constructor daarentegen niet). Ook in de implementatie komt de tilde voor.
Tekst::~Tekst()
{
cout << "delete " << ptekst << "\n"; // alleen voor test
delete [] ptekst;
}
In deze destructor wordt met delete het geheugen van de string vrijgegeven. De uitvoerbewerking staat er alleen maar om te kunnen zien wanneer de destructor uitgevoerd wordt en is daarom niet noodzakelijk.
Het gebruik van de klasse Tekst is als volgt:
#include <iostream.h>
#include "tekst.h"
void main()
{
Tekst t("hallo");
cout << t.str() << "\n";
}
De definitie van de klasse plaatsen we best in een headerbestand. Zo bevindt de definitie van Tekst zich in het bestand tekst.h. De tekst t wordt geinitialiseerd met de string "hallo". Vlak voor het einde van main() wordt de destructor opgeroepen voor het object t. met de methode str() verkrijgen we het adres van de opgeslagen tekst. De klasse Tekst kunnen we gebruiken zonder dat we iets zien van de wijze waarop de implementatie binnen de klasse is gemaakt. Deze inkapseling is één van de principes van het object georienteerd programmeren.
In het voorgaande voorbeeld is de klasse Tekst eerder beperkt. Daarom voegen we een tweetal bewerkingen bij in de klasse. We zouden deze bewerkingen kunnen bijvoegen in de vorm van klassefuncties zoals bijvoorbeeld druk() in de klasse Punt. Een ander alternatief is het veranderen van de betekenis van bewerkingstekens binnen een klasse. Dit betekent dat een bewerkingsteken een nieuwe betekenis krijgt. Volgens dit principe gaan we het = teken, += teken en het + teken koppelen aan een klassefunctie binnen de klasse Tekst. Binnen de definitie van de klasse Tekst worden de prototypes voor deze twee bewerkingen bijgevoegd.
Tekst &operator=(const Tekst &t); Tekst &operator+=(const Tekst &t); Tekst operator+(const Tekst &t);
Het zijn twee klassefuncties met een speciale naam. We laten het woord operator volgen door het bewerkingsteken dat we een nieuwe betekenis willen geven. De klassefuncties operator=, operator+= en operator+ hebben één formele parameter. Via deze parameter wordt de rechter-operand van de bewerking doorgegeven. De linker-operand wordt doorgegeven via de impliciete pointer naar het object. Met de plus operator kunnen we dan schrijven:
Tekst t1("dag ");
Tekst t2("wereld");
Tekst t3("");
t3 = t1 + t2;
Deze 'optelling' zou ook als volgt geschreven kunnen worden:
t3 = t1.operator+(t2);
Deze schrijfwijze is niet zo goed leesbaar, maar geeft wel duidelijk weer hoe de twee operands aan de optelling worden doorgegeven. De implementaties van de = en += bewerkingen zien er zo uit:
Tekst &Tekst::operator=(const Tekst &t)
{
delete ptekst;// verwijder de oude tekst
ptekst = new char [strlen(t.str() ) + 1]; // ruimte voor nieuwe tekst
strcpy(ptekst, t.str() );// kopieer tekst
return( *this );
}
Tekst &Tekst::operator+=(const Tekst &t)
{
char *poud;
poud = ptekst;// hou oude tekst opzij
// reserveer ruimte voor nieuwe tekst
ptekst = new char [strlen(poud) + strlen(t.str() ) + 1];
strcpy(ptekst, poud);// kopieer eerste tekst
strcat(ptekst, t.str() ); // voeg tweede tekst erbij
delete poud;// verwijder oude tekst
return( *this );
}
Bij elk van de twee bewerkingen wordt opnieuw dynamisch geheugen gereserveerd omdat de lengte van de nieuwe tekst, die in een object opgeslagen wordt, groter kan zijn dan de oude tekst. Telkens wordt het betrokken object via return teruggegeven. Dit is nodig omdat het resultaat van de bewerking ook van het type Tekst is.
De + bewerking kan kort geschreven worden:
Tekst Tekst::operator+(const Tekst &t)
{
Tekst nt;// nieuwe tekst
nt = *this;// kopieer eerste tekst
nt += t;// voeg tweede tekst bij
return( nt );// geef nieuwe tekst terug als resultaat
}
We maken gebruik van een lokaal Tekst object nt. Met een toekenning en daarna += bewerking worden de twee bronteksten samengevoegd in een nieuwe tekst. Deze nieuwe tekst wordt als resultaat teruggegeven. In de + bewerking wordt gebruik gemaakt van de eerder ontworpen = en += bewerkingen. Het terugkeer type is in dit geval géén referentietype.
Het gebruik van de klasse Tekst is als volgt:
#include <iostream.h>
#include "tekst.h"
void main()
{
Tekst t("hallo");
Tekst t2;
Tekst t3("o");
cout << t.str() << "\n";
t2 = t;
t2 = t + t3;
cout << t2.str() << "\n";
}
Merk op dat er een verschil is tussen de twee bewerkingen met het = teken in het volgende fragment:
{
Tekst ta("1234");
Tekst tb = ta;
Tekst tc("");
tc = ta;
}
Bij het eerste = teken wordt de copyconstructor gestart om tb te initialiseren; bij het tweede = teken wordt de klassefunctie operator=() gestart. Let op: de copyconstructor hebben we niet zelf bijgevoegd in de klasse Tekst. Daarom wordt de default copyconstructor uitgevoerd. Deze is evenwel niet geschikt voor gebruik van zodra binnen een klasse zelf dynamisch geheugen wordt bijgehouden. Dit is de reden waarom het bovenstaand fragment problemen kan geven zolang geen eigen versie van de copyconstructor binnen de klasse Tekst wordt bijgevoegd.
In vele gevallen is het nuttig om een klasse te beschouwen als een enkelvoudig type. We gaan dan gemakkelijker klassen gebruiken om daarmee nieuwe klassen samen te stellen. De techniek die we nu voorstellen is het gebruik van een bestaande klasse als type vaar dataleden van een nieuwe klasse. Het voorbeeld, dat we geven, heeft te maken met lijnen. Als we de gegevens van een lijn willen bijhouden, dan moeten we het begin- en eindpunt van de lijn opslaan. Een lijn bestaat uit twee punten of anders gezegd: de klasse Lijn bevat twee dataleden van de klasse Punt. Dit principe wordt aggregatie genoemd. We demonstreren dit met een voorbeeld.
#include <iostream.h>
#include <math.h>
#include "punt.h"
class Lijn
{
private:
Punt p1;
Punt p2;
public:
Lijn(int x1, int y1, int x2, int y2) : p1(x1,y1),
p2(x2, y2)
{
}
double lengte();
};
double Lijn::lengte()
{
double dx, dy;
dx = p1.haalx() - p2.haalx();
dy = p1.haaly() - p2.haaly();
return( sqrt(dx*dx + dy*dy) );
}
void main()
{
Lijn ln(1,2,4,6);
cout << ln.lengte() << "\n";
}
We maken in het voorbeeld een klasse Lijn. Deze klasse bevat twee dataleden van het type Punt. Hiermee wordt het verband uitgedrukt dat een lijn twee punten verbindt. De Punt dataleden p1 en p2 zijn privaat. Dit betekent dat ze niet vrij toegankelijk zijn van buiten de klasse. De klasse Lijn kent één constructor. Deze constructor verwacht vier getallen als parameter. Dit zijn de twee coördinatenparen voor de begin- en eindpunten. Voor deze constructor is een speciale schrijfwijze toegepast. Als we de constructor als volgt zouden schrijven, dan zou de compiler een foutmelding geven:
Lijn::Lijn(int x1, int y1, int x2, int y2)
{
p1.x = x1;
p1.y = y1;
p2.x = x2;
p2.y = y2;
}
Wat is er nu fout aan deze schrijfwijze? De fout heeft te maken met de beveiliging van de private dataleden. De dataleden x en y van de twee Punt objecten zijn niet vrij toegankelijk. Vanuit de Lijn constructor is er alleen maar toegang tot de publieke klassefuncties van p1 en p2. De dataleden x en y zijn privaat binnen de klasse Punt en daarom niet toegankelijk. Wel is de constructor van Punt toegankelijk. Er is echter in C++ geen mogelijkheid om rechtstreeks een constructor te starten als een functieoproep. Daarom kent C++ een speciale schrijfwijze om de dataleden van een klasse te initialiseren met een constructor. Daarom wordt de Punt constructor als volgt geschreven:
Lijn(int x1, int y1, int x2, int y2) : p1(x1,y1),
p2(x2, y2)
{
}
Na de lijst van formele parameters volgt een dubbele punt. Hierna vermelden we de namen van de dataleden die binnen Lijn voorkomen. Dit zijn p1 en p2. Na elk datalid noteren we de naam van de actuele parameters tussen haken. Zo wordt p1 geinitialiseerd met x1 en y1; p2 wordt geinitialiseerd met x2 en y2. Vanzelfsprekend moet er binnen de klasse Punt een constructor bestaan die met deze parameters overeen komt.
Met de functie lengte kan de lengte van een object van de klasse Lijn berekend worden.
Als we van plan zijn om een bepaalde klasse uit te breiden met nieuwe dataleden of klassefuncties, dan zouden we rechtstreeks in de klassedefinitie deze dataleden of klassefuncties kunnen bijvoegen. Deze strategie heeft echter nadelen, zeker als de klasse reeds een tijd in gebruik is. Het is veiliger om de klasse ongewijzigd te laten en een afleiding te maken van deze klasse. Dit betekent dat we een nieuwe klasse ontwerpen die alle eigenschappen van een bestaande klasse overerft. Deze strategie heeft twee voordelen:
de bestaande klasse hoeft niet gewijzigd te worden
de functionaliteit van een bestaande klasse wordt volledig overgenomen in de nieuwe klasse
de nieuwe klasse kan extra aangevuld worden met nieuwe dataleden en klassefuncties
Als we een klasse nodig hebben voor de voorstelling van een punt, waarbij ook nog in de klasse een naam opgeslagen wordt, dan is er een nieuwe klasse nodig. Als naam voor de nieuwe klasse kiezen we PuntmetNaam. De originele klasse Punt laten we ongewijzigd. We maken een afleiding van Punt en voegen er een naam aan toe.
De klasse definitie van PuntmetNaam ziet er als volgt uit:
#include <iostream.h>
#include "tekst.h"
#include "punt.h"
class PuntmetNaam : public Punt
{
private:
Tekst naam;
public:
PuntmetNaam(int ix, int iy, char *nm) : Punt(ix, iy), naam(nm)
{
}
void druk();
};
Op dezelfde regel als de klassenaam schrijven we de naam van de klasse waarvan we willen afleiden. Het woord public geeft aan dat het gaat om een publieke afleiding. Dit betekent dat alle private dataleden en klassefuncties binnen Punt niet toegankelijk zijn vanuit de klassefuncties van PuntmetNaam. De protected leden van Punt zijn wel toegankelijk vanuit PuntmetNaam meer niet van buiten de klasse.
Binnen de klasse PuntmetNaam wordt een extra datalid bijgevoegd: Tekst naam. Hiermee kunnen we een naam opslaan. De constructor voor PuntmetNaam krijgt een extra parameter ten opzicht van die van Punt. De derde parameter is string voor de naam. Door deze nieuwe constructor wordt de oude (overgeërfde) constructor niet meer toegankelijk. Dit is het herdefiniëren van een overgeërfde klassefunctie. De constructor bevat na de parameterlijst een dubbele punt en daarna een lijst van te initialiseren entiteiten: Punt(ix, iy), naam(nm). Met de eerste initialiseren worden de coördinaten ix en iy naar de Punt constructor doorgegeven. Met de tweede wordt de naam geinitialiseerd. We zien dus twee soorten initialisators. Met een klassenaam geven we aan met welke gegevens de superklasse wordt geinitialiseerd. Met een naam van een datalid geven we de initialisatie aan van een in de klasse zelf voorkomend klasselid.
void PuntmetNaam::druk()
{
cout << "<" << naam.str();
Punt::druk();
cout << ">";
}
Net zoals de constructor wordt ook de functie druk() opnieuw gedefinieerd. Ook hier is er een verwijzing naar een klassefunctie van de superklasse. Met Punt::druk() wordt een functie uit de superklasse opgeroepen. De naam van de functie wordt voorafgegaan door de klassenaam en twee dubbele punten. Als we dit zouden weglaten, dan ontstaat er ongewild recursie.
In het hoofdprogramma worden twee objecten gedeclareerd. Telkens wordt druk() uitgevoerd.
void main()
{
Punt p1(12,23);
PuntmetNaam p2(56, 67, "oorsprong");
p1.druk();
cout << "\n";
p2.druk();
cout << "\n";
}
Het verband tussen de twee klassen kan grafisch weergegeven worden. Deze diagrammatechniek stamt uit Universal Modelling Language(UML).
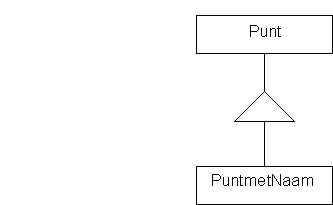
Deze tekening geeft weer dat de klasse PuntmetNaam afgeleid is van de klasse Punt. Elke rechthoek stelt een klasse voor. De naam binnen de rechthoek stelt de klassenaam voor. Eventueel kunnen de dataleden en klassefuncties elk met een aparte rechthoek bijgevoegd worden.
Het diagramma ziet er dan als volgt uit:
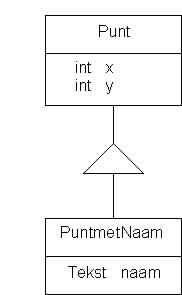
In deze vorm toont het diagramma duidelijk dat door erfenis de klasse PuntmetNaam niet alleen naam als datalid heeft maar ook x en y.
Inhoudsopgave
Door het mechanisme van de afleiding is het mogelijk om een bepaalde klasse als basisklasse te gebruiken. Van deze basisklasse worden verschillende afleidingen gemaakt. De afgeleide klassen erven allemaal het gedrag van de basisklasse. De basisklasse bevat het gemeenschappelijk gedrag van de verschillende basisklassen. Dikwijls zijn er in de basisklasse klassefuncties nodig waarvan het gedrag pas definitief in de afgeleide klassen wordt bepaald. Daarom is het nodig dat de taal C++ voorzien is van een mechanisme om de keuze van welke klassefunctie gestart wordt (die uit de basisklasse of die uit de afgeleide klasse) te verschuiven tot bij de uitvoering van het programma. Dit mechanisme heet in C++ virtuele functie. In andere talen worden ook wel de termen dynamische of late binding gebruikt.
Het concept virtuele functie is de kern van de taal C++ die het mogelijk maakt om delen van software te ontwerpen die algemeen is en onafhankelijk van alle later toe te voegen objecttypes.
Om dit concept duidelijk te maken starten we de uitleg van een voorbeeld. In dit voorbeeld maken we een algemene klasse die voor de opslag van een waarde wordt gebruikt. De virtuele functie maakt het mogelijk om specifiek gedrag in een afgeleide klasse te gebruiken vanuit een algemene klasse zonder de details te kennen van de afgeleide klassen en zonder afbreuk te doen aan de algemeenheid van de basisklasse. In het voorbeeld dat volgt willen we gewoon een waarde op het scherm drukken zonder te weten van welk specifiek getaltype de waarde is.
We maken een basisklasse die gaat dienen voor de opslag van een waarde. Als klassenaam kiezen we de naam Waarde. De eerste letter is een hoofdletter, bijgevolg is dit een klassenaam. Deze klasse moet dienen om een waarde van een nog niet gekend type op te slaan. We wensen nu nog niet vast te leggen welk type gebruik zal worden want dan zou de klasse Waarde niet algemeen bruikbaar zijn. De klasse Waarde zou moeten kunnen werken met elk mogelijk getaltype.
class Waarde
{
private:
// geen datalid
public:
// hier plaatsen we de vrij toegankelijke klassefuncties
};
De beslissing om geen datalid voor de waarde in de klasse Waarde te plaatsen is een goede beslissing. We kunnen immers het datalid voor de waarde in de afgeleide klassen plaatsen. De klasse Waarde is bedoeld als basisklasse. We zullen van deze klasse nooit objecten maken. Zo komen we meteen tot het begrip abstracte klasse. een abstracte klasse is niet bedoeld om er concrete objecten mee te maken maar wel om een algemeen gedrag te bepalen voor een reeks afgeleide klassen.
Bij dit voorbeeld is het gewenste algemeen gedrag van de klasse Waarde de mogelijkheid om de opgeslagen waarde op het scherm te drukken. Daarom plaatsen we een klassefunctie druk() in het publieke gedeelte.
class Waarde // abstracte klasse
{
public:
virtual void druk() = 0;
};
De schrijfwijze van het prototype van druk() vertoont twee nieuwe elementen:
Voor void staat het woord virtual
na de sluitende ronde haak staat = 0
Met het woord virtual geven we aan dat druk() een virtuele functie is. De precieze werking wordt later duidelijk. Na druk() staat er = 0. Hiermee geven we aan dat we voor druk() nog geen implementatie voorzien. Deze implementatie moet ingevuld worden in de verschillende afleidingen van de basisklasse. Deze = 0 is niet nodig om de functie virtueel te maken maar wel om de klasse abstract te maken.
Van een abstracte klasse mogen we geen objecten maken. Wel is het mogelijk om een pointer of een referentie naar een abstracte klasse te maken.
Waarde w1;// FOUT Waarde *pw1// GOED
We maken twee afleidingen van de basisklasse. Een voor de opslag van een geheel getal en een voor de opslag van een reëel getal.
class IWaarde : public Waarde
{
private:
int intwaarde;
public:
IWaarde(int iw) : intwaarde(iw)
{
}
virtual void druk();
};
class FWaarde : public Waarde
{
private:
double floatwaarde;
public:
FWaarde(double iw) : floatwaarde(iw)
{
}
virtual void druk();
};
Elke van deze afleidingen krijgt een privaat datalid voor de opslag van de waarde. Het type van de waarde is telkens verschillend. In elke afgeleide klasse is er een constructor voorzien om het object te initialiseren. In elke afgeleide klasse wordt ook het prototype van druk() bijgevoegd. Dit betekent dat de functionaliteit van de functie druk() in de verschillende afgeleide klassen willen invullen. Het woord virtual wordt herhaald voor het prototype, dit is niet verplicht. Wel is het verplicht om bij het herdefiniëren van een virtuele functie in een afgeleide klasse dezelfde formele parameters te voorzien als in de basisklasse.
De twee druk() functies verschillen omdat de te drukken waarden van een ander type zijn:
void IWaarde::druk()
{
cout << "geheel " << intwaarde;
}
void FWaarde::druk()
{
cout << "reeel " << floatwaarde;
}
In programmeertalen zoals Pascal, C en C++ is er een strikte typecontrole door de compiler. De omzetting van het ene type naar het andere type is niet altijd toegelaten. Op enkele uitzonderingen na is het verboden om verschillende types te gebruiken in toekenningen. In C en C++ kan deze beperking natuurlijk omzeild worden door de geforceerde omzetting (cast), maar deze programmeertechniek is niet elegant en veroorzaakt veel sneller fouten op. In C++ wordt de cast-bewerking grotendeels overbodig door de mogelijkheid om in beperkte mate toch toekenningen te doen tussen verschillende types.
In C++ is het toegelaten om een toekenning te doen van pointers (dit geldt ook voor het referentietype) van een verschillende type. Er is wel een voorwaarde: de pointer aan de linkerzijde van de toekenning moet van een type zijn dat als superklasse voorkomt van de klasse van de pointer aan de rechterzijde van de toekenning. Deze uitzondering is de enige op de regel die zegt dat de twee types aan beide zijden van een toekenning gelijk moeten zijn.
Een voorbeeld maakt dit duidelijk:
Waarde *pw; IWaarde *piw; FWaarde *pfw; pw = piw; // ok, Waarde is de basisklasse van IWaarde pw = pfw; // ok, Waarde is de basisklasse van FWaarde piw = pw; // fout, Iwwaarde is geen basisklasse van Waarde
Deze compatibiliteit tussen verschillende pointertypes is nodig om gebruik te kunnen maken van de virtuele functies. Ter verduidelijking is hier nog het schema dat het verband tussen de verschillende klassen uit het voorbeeld weergeeft.
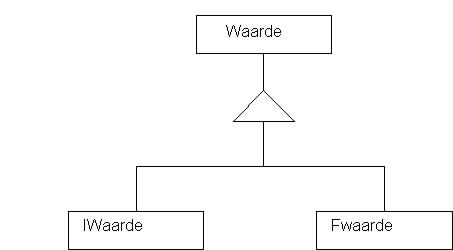
Als we een virtuele klassefunctie oproepen via een pointer naar de basisklasse komt effect van de virtuele functie tot uiting.
IWaarde i1(5); FWaarde f1(7.9); Waarde *pw; pw = &i1; pw->druk(); pw = &f1; pw->druk();
De pointer pw is een pointer naar een Waarde object. De declaratie en het gebruik van pw is toegelaten. Objecten van een abstracte klasse mogen niet, pointers naar een abstracte klasse mogen wel. Bij de eerste toekenning wijst pw naar een IWaarde object. Bij de oproep van druk() wordt de IWaarde variant van druk() gestart. Op het scherm verschijnt 5. Bij de tweede toekenning wijst pw naar een FWaarde object. Bij de tweede oproep van druk() wordt de FWaarde variant van druk() gestart. Op het scherm verschijnt 7.9. In elk object van een klasse met tenminste één virtuele functie zit extra informatie opgeslagen over de klasse van het object. Door deze informatie is het mogelijk dat bij de oproep van druk() bepaald wordt welke variant uit een van de afgeleide klassen wordt gestart.
Dit is de volledige tekst van het voorbeeld:
#include <iostream.h>
class Waarde // abstracte klasse
{
public:
virtual void druk() = 0;
};
class IWaarde : public Waarde
{
private:
int intwaarde;
public:
IWaarde(int iw) : intwaarde(iw)
{
}
virtual void druk();
};
class FWaarde : public Waarde
{
private:
double floatwaarde;
public:
FWaarde(double iw) : floatwaarde(iw)
{
}
virtual void druk();
};
void IWaarde::druk()
{
cout << "geheel " << intwaarde;
}
void FWaarde::druk()
{
cout << "reeel " << floatwaarde;
}
void toon(Waarde *pw)
{
pw->druk();
}
void main()
{
//Waarde ww; fout Waarde is een abstracte klasse
IWaarde i1(5);
FWaarde f1(7.9);
toon( &i1 );
toon( &f1 );
Waarde *pw1 = new IWaarde(256);
Waarde *pw2 = new FWaarde(1.0/3.0);
pw1->druk();
pw2->druk();
}
In het voorbeeld wordt het principe van de virtuele functie tweemaal gedemonstreerd. Eenmaal worden adressen van objecten aan de functie toon() doorgegeven. De functie toon is ontwerpen met het doel de waarde van het doorgegeven object te tonen. Het object wordt doorgegeven via zijn adres. Dit is efficiënter dan de volledige waarde door te geven. De functie toon() verwacht het adres van een Waarde object. Vermits Waarde een abstracte basisklasse is van IWaarde of FWaarde, kan het doorgegeven object een IWaarde of een FWaarde object zijn. Gezien vanuit de functie toon() kan niet op voorhand voorspeld worden of het doorgegeven object een IWaarde of een FWaarde. Dit is de reden waarom we een virtuele functie gebruiken als mechanisme voor de start van druk(). Binnen toon() is er geen kennis nodig over de mogelijke specialisaties van Waarde. We kunnen dit voorbeeld besluiten met te zeggen dat een Waarde object toonbaar is; de waarde van het object kan verschillend zijn in de verschillende afleidingen. Dit verschil in gedrag wordt vastgelegd in de implementatie van de afgeleide klassen.
Het is mogelijk om binnen de klassedeclaratie voorzieningen te treffen om constante objecten correct te behandelen. Een constant object is een object dat niet wijzigbaar is. Dit geven we aan bij de declaratie met het woord const. Bijvoorbeeld:
const Punt pc(45,67);
Het object pc is niet wijzigbaar; bijgevolg mogen voor dit object alleen klassefuncties gestart worden die garanderen dat er geen van de dataleden gewijzigd wordt. In de klassedeclaratie van Punt zien we na sommige functienamen het woord const staan. Hiermee wordt aangegeven dat de functie gaan dataleden wijzigt. Indien toch een wijziging van een datalid binnen een klassefunctie gebeurt, wordt dit als fout door de compiler gemeld.
#include <iostream.h>
// werken met constante objecten
class Punt
{
private:
int x;
int y;
public:
Punt(int ix = 0, int iy = 0) : x(ix), y(iy)
{
}
void druk() const
{
cout << "<" << x <<"," << y <<">" << endl;
}
// geen wijzigingen van dataleden toegelaten in const functies
int haalx() const
{
// x++; fout
return(x);
}
int haaly() const
{
return(y);
}
void zetx(int ix)
{
x = ix;
}
void zety(int iy)
{
y = iy;
}
};
void main()
{
Punt p1(2,3);
const Punt p2(4,5);
p1.druk();
p2.druk();
// p2.zetx(8); fout p2 kan niet gewijzigd worden
}
In main worden twee objecten gedeclareerd: p1 en p2. De laatste is een constante. Dit betekent dat alleen const functies bij dit object gestart kunnen worden.
Statische dataleden zijn leden waarvoor slechts éénmaal geheugenruimte wordt gereserveerd. In het volgende voorbeeld bestaat er binnen de klasse Punt een statisch dataveld aantal. De geheugenruimte bestaat slechts éénmaal. Elk object van het type Punt heeft een eigen x en y veld, maar het veld aantal is gemeenschappelijk voor de hele klasse. De toegang tot aantal verloopt niet via een object maar wel via de klasse. Het veld aantal wordt in dit voorbeeld gebruikt om bij te houden hoeveel objecten van de klasse Punt er bestaan. Deze boekhouding wordt met behulp van de constructor en destructor georganiseerd. Telkens als we de constructor of destructor doorlopen wordt aantal met 1 verhoogd of verlaagd. Door het feit dat aantal privaat is, zijn we er zeker van dat aantal niet buiten de klasse gewijzigd kan worden. Daarom zijn er ook toegangsfuncties bijgevoegd. Dit zijn init_aantal() en haal_aantal(). Dit zijn statische functies. Dit betekent dat ze niet in het kader van een object worden gestart, maar wel binnen de klasse.
De geheugenruimte voor een statisch datalid moet expliciet gereserveerd worden.
#include <iostream.h>
// statische leden in een klasse
class Punt
{
private:
int x;
int y;
static int aantal;
public:
Punt(int ix = 0, int iy = 0) : x(ix), y(iy)
{
aantal++;
}
~Punt()
{
aantal--;
} // destructor
void druk() const;
int haalx() const
{
return(x);
}
int haaly() const
{
return(y);
}
void zetx(int ix)
{
x = ix;
}
void zety(int iy)
{
y = iy;
}
// statische klassefuncties worden zonder this opgeroepen
static void init_aantal()
{
aantal = 0;
}
static int haal_aantal()
{
return( aantal);
}
};
void druk();
void Punt::druk() const
{
::druk();// de twee dubbele punten zijn nodig voor recursie
// te vermijden
cout << "<" << x <<"," << y <<">" << endl;
}
void druk()
{
cout << "cv10 ";
}
// de geheugenruimte voor statische dataleden
// moet expliciet gereserveerd worden
int Punt::aantal;
void fu()
{
Punt p1(2,3);
const Punt p2(4,5);
p1.druk();
p2.druk();
cout << "aantal punten " << Punt::haal_aantal() << endl;
}
void main()
{
// oproep zonder object
Punt::init_aantal();
fu();
cout << "aantal punten " << Punt::haal_aantal() << endl;
}
In dit voorbeeld wordt gedemonstreerd hoe het mogelijk om de index bij arrays te controleren. Het is mogelijk om binnen een klasse een nieuwe betekenis te geven aan de operator[]. We kunnen zo een klasse laten werken als een array uit C of Pascal. Dit geeft ons de mogelijkheid om de waarde van de index te controleren.
De klasse Reeks heeft een private pointer naar een array van int's. Deze array wordt gereserveerd in de constructor en wordt terug vrijgegeven in de destructor. We houden binnen de klassen ook de lengte bij en het datalid lengte. De functie controle_index() wordt gebruikt om de index te controleren en eventueel een foutmelding te geven. Bij fout wordt het programma afgebroken met exit();. De operator[] ontvangt de index, controleert die en geeft dan de gewenste dat terug. Het prototype ziet er als volgt uit:
int& operator [] ( unsigned long index )
Merk op dat het terugkeertype een referentietype is. Dit is nodig om de inhoud van de reeks te kunnen wijzigen.
#include <iostreams.h>
#include <stdlib.h>
// een toepassing van de [] operator
class Reeks
{
private:
int *data;
unsigned long lengte;
protected:
void controle_index( unsigned long index, int lijnnr )
{
if ( index >= lengte )
{
cout << "arrayindex-fout in regel "<< lijnnr<< " index " << index << endl;
exit(1);
}
}
public:
Reeks(unsigned long grootte)
{
lengte = grootte;// hou de grootte bij
data = new int[grootte];// reserveer ruimte
cout << "Reeks constructor\n";
}
~Reeks()
{
delete [] data;// geef reeks vrij
cout << "Reeks destructor\n";
}
int& operator [] ( unsigned long index )
{
controle_index( index , __LINE__ );// eerst controle
return data[index];
}
};
void main()
{
Reeks lijst(10);
for (int i=0; i<20; i++)
{
lijst[i] = i;
cout << lijst[i];
}
}
In main() wordt een reeks van 10 gehele getallen gecreëerd. De lijst wordt opgevuld met getallen en hier ontstaat een fout: bij i = 10 wordt het programma afgebroken.
Het voorgaande voorbeeld was niet flexibel genoeg. Daarom wordt de klasse Reeks algemener gemaakt door sjablonen (templates) te gebruiken. Hierdoor is Reeks onafhankelijk van de opgeslagen soort. Reeks in niet meer een lijst van int's maar wel van klasse T elementen. Dit zien we aan de naam van de klasse:
template<class T> class Reeks
De klasse Reeks kent nu een typeparameter T. Hiermee kunnen we aangeven van welke klasse de gegevens zijn. In heel de klasse is int door T vervangen. De klasse Reeks is hierdoor algemener geworden. Voor het overige is Reeks niet gewijzigd.
#include <iostreams.h>
#include <stdlib.h>
// reeks.h een algemene reeks
template<class T>
class Reeks
{
private:
T *data;
unsigned long lengte;
protected:
void controle_index( unsigned long index, int lijnnr )
{
if ( index >= lengte )
{
cout << "arrayindex-fout in regel "<< lijnnr<< " index " << index << endl;
exit(1);
}
}
public:
Reeks(unsigned long grootte)
{
lengte = grootte;
data = new T[grootte];
cout << "Reeks<T> constructor\n";
}
~Reeks()
{
delete [] data;
cout << "Reeks<T> destructor\n";
}
T& operator [] ( unsigned long index )
{
controle_index( index , __LINE__ );
return data[index];
}
};
In het hoofdprogramma maken we een reeks van int getallen. We moeten het type int als parameter meegeven:
Reeks<int>lijst(10); Reeks<double>lijst2(100); Reeks<Punt>lijst3(5);
Het actuele type wordt vermeld tussen kleiner en groter-dan tekens.
#include <iostream.h>
#include <stdlib.h>
#include "reeks.h"
// sjablonen: algemene reeksen
void main()
{
Reeks<int> lijst(10);
for (int i=0; i<20; i++)
{
lijst[i] = i;
cout << lijst[i];
}
}
De reeks in dit voorbeeld is zo algemeen geworden dat we dit type in veel gevallen kunnen toepassen. We hoeven niet meer voor elke soort gegevens een nieuwe reeks te ontwerpen
Uitzonderingen (exceptions) laten toe om fouten op een gepaste manier af te handelen. In de voorgaande voorbeelden wordt de arrayfout drastisch afgehandeld. Het programma wordt gewoon afgebroken. Door gebruik te maken van uitzonderingen kan de foutafhandeling aangepast worden aan de noden van de gebruiker van een klasse. Binnen de klasse wordt in een foutsituatie de throw bewerking uitgevoerd. Hiermee wordt de fout aan de gebruiker van de klassen gemeld.
throw Fout();
Aan throw wordt een object van een klasse meegegeven. Hiermee wordt de fout geïdentificeerd. Fout() is de oproep van de standaard constructor zonder parameter. Om aan te geven dat we op mogelijke fouten reageren, definiëren we een try-blok.
try
{
}
catch(Fout)
{
// foutafhandeling
}
Alle acties binnen het try-blok kunnen onderbroken worden door een throw. Alle bestaande objecten worden automatisch afgebroken door hun destructor. Dit geldt niet voor objecten die we dynamisch met new hebben gereserveerd. Het kan daarom nodig zijn om pointers naar een klasse op te nemen binnen een nieuwe klasse zodat de destructor van deze nieuwe klassen voor het vrijgeven van de pointer zorgt.
#include <iostream.h>
// uitzonderingen
class Fout // dit is de foutklasse
{
};
class Gegeven
{
private:
int getal;
public:
Gegeven(int geg=0) : getal(geg)
{
cout << "Gegeven(" << getal<<") constructor" << endl;
}
~Gegeven()
{
cout << "Gegeven(" << getal<<") destructor" << endl;
}
};
void fu()
{
Gegeven g = 2;
Gegeven *pg;
pg = new Gegeven(3);
throw Fout();// g wordt afgebroken
// pg niet
}
void fu2()
{
Gegeven h = 4;
fu();// h wordt afgebroken
}
void main()
{
try// probeer fu2() te starten
{
fu2();
}
catch(Fout)// van fouten hier op
{
cout << "fout" << endl;
}
}
In de functie fu() wordt een throw uitgevoerd. Hierdoor worden h en g automatisch afgebroken. Dit is niet het geval voor het object dat door pg wordt aangewezen. In main() komen we terecht in het catch-blok en wordt de nodige actie ondernomen.
De algemene reeks is nu met uitzonderingen beveiligd. De foutklasse Arrayfout houdt de foutmelding in tekstvorm bij. Binnen controle_index() kan een throw gestart worden.
// sjabloon Reeks met uitzondering
class Arrayfout
{
private:
char *melding;
public:
Arrayfout(char *p) : melding(p)
{
}
char *foutmelding()
{
return( melding );
}
};
template <class T>
class Reeks
{
private:
T *data;
unsigned long lengte;
protected:
void controle_index( unsigned long index, int lijnnr )
{
if ( index >= lengte )
{
throw Arrayfout("arrayindex-fout");
}
}
public:
Reeks(unsigned long grootte)
{
lengte = grootte;
data = new T[grootte];
cout << "Reeks constructor\n";
}
~Reeks()
{
delete [] data;
cout << "Reeks destructor\n";
}
T& operator [] ( unsigned long index )
{
controle_index( index , __LINE__ );
return data[index];
}
};
In het hoofdprogramma is een try en catch-blok bijgevoegd. Hiermee kunnen we de arrayfout opvangen.
#include <iostream.h>
#include <string.h>
#include "vreeks.h"
void main()
{
try// probeer
{
Reeks<int> lijst(10);// een lijst van 10 int's
for (int i=0; i<20; i++)
{
lijst[i] = i;
cout << lijst[i];
}
}
catch(Arrayfout &f)// vang arrayfout
{
cout << f.foutmelding();// toon de foutmelding
}
}
Het volgende voorbeeld is het bestand nvreeks.h. Deze template klasse is in staat om de capaciteit van de opslag te vergroten zonder dat er gevens verloren gaan.
Figuur 15.1. nvreeks.h
#ifndef _NVREEKS_H
#define _NVREEKS_H
// template Reeks met exception en aantal
// 26/ 3/96 rl
// 11/ 2/97
// 7/10/97 rl betere test startgrootte in constructor (<=0)
class Arrayfout
{
};
template <class T>
class Reeks
{
private:
T *data;
int lengte; // gereserveerde grootte
int aantal; // aantal elementen in reeks
protected:
void controle_index( int index, int lijnnr )
{
if ( index >= lengte )
{
throw Arrayfout();
//cout << "arrayindex-fout";
//exit(1);
}
}
public:
Reeks(int grootte=1) : aantal(0)
{
if (grootte <= 0)
grootte = 1;
lengte = grootte;
data = new T[grootte];
}
~Reeks()
{
delete [] data;
}
T& operator [] (int index )
{
controle_index( index , __LINE__ );
return data[index];
}
void voegbij(T &element)
{
if (aantal >= lengte)
{
// reserveer nieuwe tabel en copieer
lengte *= 2; // dubbele lengte
T *nw_data = new T[lengte];
for (int i=0; i<aantal; i++)
nw_data[i] = data[i];
delete [] data;
data = nw_data;
}
data[aantal++] = element;
}
int grootte()
{
return( aantal );
}
};
#endif
In het volgende testprogramma wordt het gebruik van deze reeks gedemonstreerd.
Figuur 15.2. cppvb17.cpp
// cppvb17.cpp
#include <stdio.h>
#include "nvreeks.h"
int main()
{
try
{
Reeks<int> tab(10);
for (int i=0; i<20; i++)
{
int sq = i*i;
tab.voegbij(sq);
}
for (int i=0; i<tab.grootte(); i++)
{
printf("%d: %d\n", i, tab[i]);
}
}
catch(Arrayfout)
{
printf("Arrayfout\n");
}
catch(...)
{
printf("onbekende fout\n");
}
}
In het bovenstaand programma zullen de catch blokken nooit bereikt worden omdat de reeks automatisch vergroot wordt. Er wordt gestart met grootte 10 en geëindigd met 20.
In dit voorbeeld is voor het inhoudstype T gekozen voor de pointer Info *.
Figuur 16.1. cppvb18.cpp
#include <stdio.h>
#include "nvreeks.h"
class Info
{
public:
Info(int g): getal(g)
{
}
void toon()
{
printf("%d\n", getal);
}
private:
int getal;
};
int main()
{
try
{
Reeks<Info *> tab(10);
for (int i=0; i<22; i++)
{
int sq = i*i;
tab.voegbij(new Info(sq));
}
// alle Info's tonen
for (int i=0; i<tab.grootte(); i++)
{
tab[i]->toon();
}
// alle Info's vrijgeven
for (int i=0; i<tab.grootte(); i++)
{
tab[i]->toon();
}
}
catch(Arrayfout)
{
printf("Arrayfout\n");
}
catch(...)
{
printf("onbekende fout\n");
}
}
In dit voorbeeld is de container een klassevariabele.
Figuur 17.1. cppvb19.cpp
#include <stdio.h>
#include "nvreeks.h"
class Info
{
public:
Info(int g): getal(g)
{
}
void toon()
{
printf("%d\n", getal);
}
private:
int getal;
};
class Gegevens
{
public:
Gegevens(int n): lijst(n)
{
for (int i=0; i<n; i++)
{
lijst.voegbij(new Info(i * i));
}
}
void toon()
{
printf("Gegevens:\n");
for (int i=0; i<lijst.grootte(); i++)
{
lijst[i]->toon();
}
}
~Gegevens()
{
for (int i=0; i<lijst.grootte(); i++)
{
delete lijst[i];
}
}
private:
Reeks<Info *> lijst;
};
int main()
{
try
{
Gegevens g(22);
g.toon();
}
catch(Arrayfout)
{
printf("Arrayfout\n");
}
catch(...)
{
printf("onbekende fout\n");
}
}
In dit voorbeeld wordt het gebruik van vector getoond.
Figuur 18.1. stlvb1.cpp
#include <vector>
using namespace std;
class Punt
{
private:
int x;
int y;
public:
Punt(int ix, int iy) : x(ix), y(iy)
{
}
void toon()
{
printf("%d, %d\n", x, y);
}
};
int main()
{
vector<Punt *> lijst;
for (int i=0; i<20; i++)
{
Punt *p = new Punt(1+i,2+i);
lijst.push_back(p);
}
for (int i= 0;i<lijst.size(); i++)
{
lijst[i]->toon();
}
vector<Punt *>::iterator it = lijst.begin();
while (it != lijst.end())
{
Punt *q = *it;
q->toon();
it++;
}
for (int i= 0;i<lijst.size(); i++)
{
delete lijst[i];
}
}
Hier is het voorgaande voorbeeld overgenomen en vector door list vervangen. De herhaling waarbij de rechte haken [] worden gebruikt voor indexering is geschrapt. Bij list en andere containers is dit niet mogelijk.
Figuur 18.2. stlvb2.cpp
#include <list>
using namespace std;
class Punt
{
private:
int x;
int y;
public:
Punt(int ix, int iy) : x(ix), y(iy)
{
}
~Punt()
{
printf("~Punt\n");
}
void toon()
{
printf("%d, %d\n", x, y);
}
};
int main()
{
list<Punt *> lijst;
for (int i=0; i<20; i++)
{
Punt *p = new Punt(1+i,2+i);
lijst.push_back(p);
}
list<Punt *>::iterator it = lijst.begin();
while (it != lijst.end())
{
Punt *q = *it;
q->toon();
it++;
}
it = lijst.begin();
while (it != lijst.end())
{
Punt *q = *it;
delete q;
it++;
}
}
In dit voorbeeld wordt een ingenieus systeem toegepast om geheugenlekken op te sporen. Elke klasse moet afgeleid worden van GElem. Er moet ook een enkel globaal GLijst gemaakt worden. Op het einde van het programma wordt automatisch gemeld welke objecten nog niet vrijgegeven worden.
Figuur 18.3. dbg-geheugen.h
// dbg-geheugen.h
// $Date: 2005/02/04 10:15:11 $
#ifndef DBG_GEHEUGEN
#include <stdio.h>
#include <list>
using namespace std;
// deze klasse is een element bedoeld om in een lijst
// op te slaan. Omdat vanuit deze klasse verwezen
// wordt naar de lijst klasse en omdat dit compilatiefouten
// geeft, wordt de lijstklasse als parameter class T doorgegeven
template<class T>
class GElem_tm // dit is de elementklasse met template parameter
{
public:
GElem_tm()
{
printf("GElem()\n");
T::haal().voegbij(this); // T wordt GLijst
}
~GElem_tm()
{
printf("~GElem()\n");
T::haal().verwijder(this); // T wordt GLijst
}
// deze functie moet een andere invulling
// krijgen in de afleiding
virtual void toon()
{
printf("GElem\n");
}
};
class GLijst; // voorwaartse declaratie van een klasse
// hiermee wordt de compiler verteld dat
// deze naam een klasse is
// dit is de elementklasse met template parameter
// de actuele parameter is GLijst
typedef GElem_tm<GLijst> GElem;
// de klasse GLijst houd een lijst van GElem bij
// elke in de toepassing gebruikte klasse
// moet overerven van GElem
class GLijst
{
public:
GLijst()
{
printf("GLijst()\n");
}
void voegbij(GElem *em)
{
lijst.push_back(em);
}
void verwijder(GElem *em)
{
lijst.remove(em);
}
void toon()
{
printf("GLijst:\n");
printf("lijst van nog niet vrijgegeven objecten\n");
list<GElem *>::iterator it = lijst.begin();
while (it != lijst.end())
{
GElem *q = *it;
q->toon();
it++;
}
}
~GLijst()
{
printf("~GLijst\n");
list<GElem *>::iterator it = lijst.begin();
while (it != lijst.end())
{
printf("element vergeten vrij te geven\n");
GElem *q = *it;
q->toon();
/* deze delete zorgt erook voor dat het GElem uit
de lijst verwijderd is. Om problemen te vermijden
met it laten we it steeds naar het begin van de lijst
wijzen
e
*/
// verwijder GElem uit lijst en geheugen
delete *it;
// het begin van de lijst is veranderd, daarom opnieuw instellen
it = lijst.begin();
// dit zou fout zijn
// it++;
}
}
// deze functie geeft een referentie naar het
// ene en enige GLIijst object terug
static GLijst &haal()
{
return geheugen;
}
// dit is een statisch GLijst object
static GLijst geheugen;
private:
list<GElem *> lijst;
};
#endif
Figuur 18.4. stlvb3.cpp
// $Date: 2005/02/04 10:15:11 $
#include <stdio.h>
#include "dbg-geheugen.h"
using namespace std;
// dit is een klasse die getest wordt
// tegen geheugenlekken, vandaar
// de erfenis van GElem
class Punt : public GElem
{
private:
int x;
int y;
public:
Punt(int ix, int iy) : x(ix), y(iy)
{
}
~Punt()
{
printf("~Punt\n");
}
void toon()
{
printf("Punt: %d, %d\n", x, y);
}
};
// dit is het object met daarin de lijst
// de contsructor en destructor worden
// automatisch gestart
GLijst GLijst::geheugen;
int main()
{
printf("start\n");
Punt *p1 = new Punt(5,6);
Punt *p2 = new Punt(7,8);
Punt *p3 = new Punt(10,10);
// deze toon geeft al aan dat er
// Punt objecten in het geheugen
// zitten
GLijst::geheugen.toon();
printf("einde\n");
// nadat deze accolade overschreden is,
// wordt de destructor van GLijst gestart
// en die meldt dat er nog 3 objecten
// in het geheugen zitten
}
Inhoudsopgave
Dit is een klein Qt voorbeeld met een paint() functie.
#include <qapplication.h>
#include <qpushbutton.h>
#include <qfont.h>
#include <qpainter.h>
class MyWidget : public QWidget
{
public:
MyWidget( QWidget *parent=0, const char *name=0 );
protected:
void paintEvent( QPaintEvent * );
};
MyWidget::MyWidget( QWidget *parent, const char *name )
: QWidget( parent, name )
{
setMinimumSize( 200, 120 );
setMaximumSize( 200, 120 );
QPushButton *quit = new QPushButton( "Quit", this, "quit" );
quit->setGeometry( 62, 40, 75, 30 );
quit->setFont( QFont( "Times", 18, QFont::Bold ) );
connect( quit, SIGNAL(clicked()), qApp, SLOT(quit()) );
}
void MyWidget::paintEvent( QPaintEvent * )
{
QString s = "Hallo";
QPainter p( this );
p.drawText( 20, 20, s );
}
int main( int argc, char **argv )
{
QApplication a( argc, argv );
MyWidget w;
w.setGeometry( 100, 100, 200, 120 );
a.setMainWidget( &w );
w.show();
return a.exec();
}
/****************************************************************
**
** Qt figuren vb
**
****************************************************************/
#include <qapplication.h>
#include <qpushbutton.h>
#include <qfont.h>
#include <qpainter.h>
#include <vector>
using namespace std;
class Figuur
{
public:
Figuur(int ix, int iy) : x(ix), y(iy)
{
}
virtual void teken(QPainter *p, int dx, int dy) = 0;
protected:
int x;
int y;
};
class Lijn : public Figuur
{
public:
Lijn(int ix1, int iy1, int ix2, int iy2) : Figuur(ix1, iy1), x2(ix2), y2(iy2)
{
}
void teken(QPainter *p, int dx, int dy);
private:
int x2;
int y2;
};
class Rechthoek : public Figuur
{
public:
Rechthoek(int ix1, int iy1, int ix2, int iy2) : Figuur(ix1, iy1), x2(ix2), y2(iy2)
{
}
void teken(QPainter *p, int dx, int dy);
private:
int x2;
int y2;
};
class SFiguur : public Figuur
{
public:
SFiguur(int ix, int iy) : Figuur(ix, iy)
{
}
void voegbij(Figuur *f);
void teken(QPainter *p, int dx, int dy);
private:
vector<Figuur *> figuren;
};
void SFiguur::voegbij(Figuur *f)
{
figuren.push_back(f);
}
void Lijn::teken(QPainter *p, int dx, int dy)
{
p->drawLine(dx + x, dy + y, dx + x2, dy + y2);
}
void Rechthoek::teken(QPainter *p, int dx, int dy)
{
p->drawRect(dx + x, dy + y, x2 - x, y2 - y);
}
void SFiguur::teken(QPainter *p, int dx, int dy)
{
for (int i= 0;i<figuren.size(); i++)
{
figuren[i]->teken(p, dx + x, dy + y);
}
}
class FVenster : public QWidget
{
public:
FVenster( QWidget *parent=0, const char *name=0 );
protected:
void paintEvent( QPaintEvent * );
private:
SFiguur *fig;
};
FVenster::FVenster( QWidget *parent, const char *name )
: QWidget( parent, name )
{
setMinimumSize( 400, 300 );
setMaximumSize( 400, 300 );
// maak een SFiguur
fig = new SFiguur(100, 100);
fig->voegbij(new Rechthoek(0, 30, 30, 60));
fig->voegbij(new Lijn(0, 30, 15, 0));
fig->voegbij(new Lijn(15, 0, 30, 30));
}
void FVenster::paintEvent( QPaintEvent * )
{
QString s = "Hallo";
QPainter p( this );
fig->teken(&p, 0, 0);
}
int main( int argc, char **argv )
{
QApplication a( argc, argv );
FVenster w;
w.setGeometry( 100, 100, 200, 120 );
a.setMainWidget( &w );
w.show();
return a.exec();
}Dit is de Makefile om beide voorbeelden te compileren. Je ziet dat er gelinkt wordt met de qt bibliotheek die zich in de directory /usr/lib/qt/lib bevindt.
gpainter: qpainter.o g++ -o qpainter qpainter.o -L/usr/lib/qt/lib -lqt qpainter.o: qpainter.cpp g++ -c qpainter.cpp figuren: figuren.o g++ -o figuren figuren.o -L/usr/lib/qt/lib -lqt figuren.o: figuren.cpp g++ -c figuren.cpp
Bjarne Stroustrup, The C++ Programming Language Second Edition, Addison-Wesley Publishing Company, Reading, Massachusetts, 1993
Stanley B. Lippman, C++ Inleiding en Gevorderd Programmeren, Addisson-Wesley Publishing Company, Amsterdam, 1990
Borland C++ 4.0 Programmer's Guide, Borland International Inc. , 1993
Wolfgang Pree, Design Patterns for Object-Oriented Software Development, Addison-Wesley Publishing Company, Wokingham England, 1994